CNIC has made significant progress in the development of graph neural network frameworks
Graph Neural Networks (GNNs) have demonstrated tremendous potential in critical domains such as biomedicine, knowledge graphs, and AI for Science (AI4S). However, as real-world applications increasingly involve graphs scaling to hundreds of millions—or even billions—of edges, GNN training faces severe communication overhead and computational bottlenecks.
Recently, addressing these challenges, the Artificial Intelligence Division of our center developed the TAC framework, which systematically integrates three key techniques: Affinity-aware Cache-filling with Insertion (ACI), a sparsity-aware Hybrid Matrix storage format (HybridMatrix), and a multi-level fine-grained training pipeline. TAC effectively reduces global communication overhead by enhancing cache locality and leverages Tensor Cores to efficiently accelerate sparse matrix computations. Experimental results demonstrate significant end-to-end performance improvements over existing frameworks.
This work has been accepted by the 31st ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP 2026). PPoPP is a CCF Class-A recommended conference and a premier venue in the fields of high-performance computing and systems. This research was supported by the National Key R&D Program of China (Grant No. 2023ZD0120602) and the Chinese Academy of Sciences Pioneer Initiative (Grant No. XDB0500101). The first author is Engineer Zhiqiang Liang from our center; the corresponding authors are Senior Engineer Jue Wang and Professor Yanguang Wang; and Ph.D. student Hongyu Gao is a co-first author.
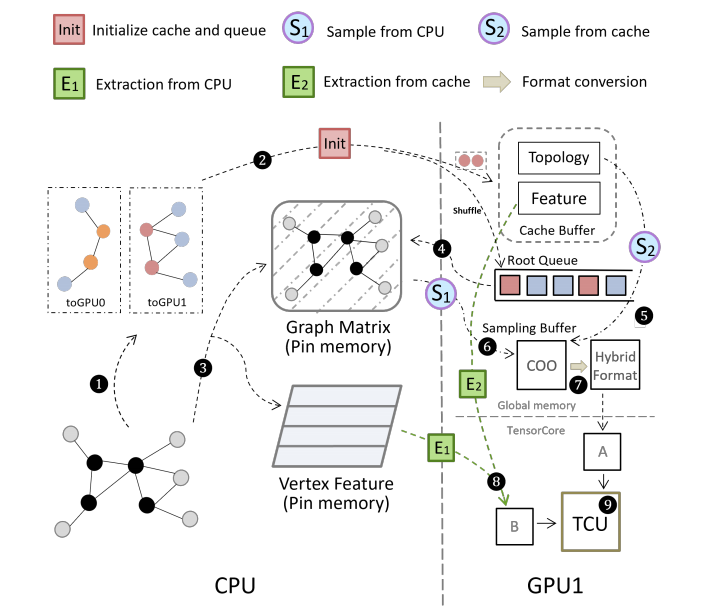
The overview of TAC system
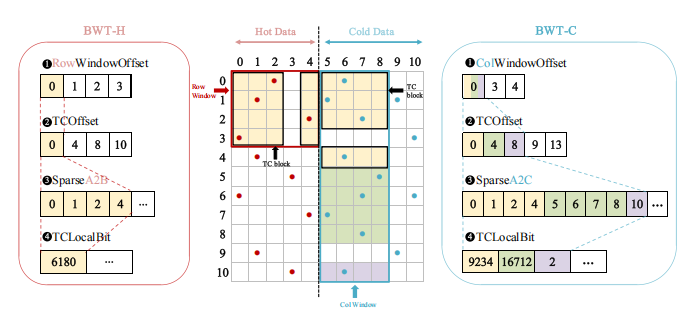
HybridMatrix format
[1] Zhiqiang Liang,Hongyu Gao,Jue Wang,Fang Liu,Xingguo Shi,Junyu Gu,Peng Di,San Li,Lei Tang,Chunbao Zhou,Lian Zhao,Yangang Wang,Xuebin Chi. TAC: Cache-based System for Accelerating Billion-Scale GNN Training on Multi-GPU Platform. ACM SIGPLAN Symposium on Principles & Practice of Parallel Programming(PPoPP’26).