CNIC has made new progress in accelerating distributed graph neural network training.
Graph neural networks can handle complex graph-structured data and have wide application prospects in fields such as chip design, energy planning, and recommendation systems. With the growth in data scale and complexity, a single computational unit is no longer capable of meeting the processing needs of large-scale graph data. Although using multiple GPUs to accelerate GNN training has gradually become mainstream, distributed training of full-batch GNNs still faces challenges such as severe load imbalance and high communication overhead.
To address these challenges, researchers from the AI Departments of CNIC developed an efficient full-batch training system called ParGNN. This system adopts an over-partition approach and utilize profiler information in pre-execution to guide workload to alleviate the computational load imbalance. ParGNN implements a novel subgraph pipelining algorithm that overlaps the computation and communication processes, significantly improving efficiency without affecting the training accuracy of GNNs. Experiments show that compared to the current state-of-the-art solutions DGL and Pipe GCN, ParGNN not only achieves the highest training accuracy but also reaches the preset accuracy target in the shortest time.
This work has been accepted by the 62nd International Design Automation Conference (DAC 2025), a highly prestigious conference (CCF-A). The research was supported by the National Key Research & Development Program of China (Grant No. 2023YFB4502303) and the Strategic Priority Research Program of Chinese Academy of Sciences (Grant No. XDB0500103).
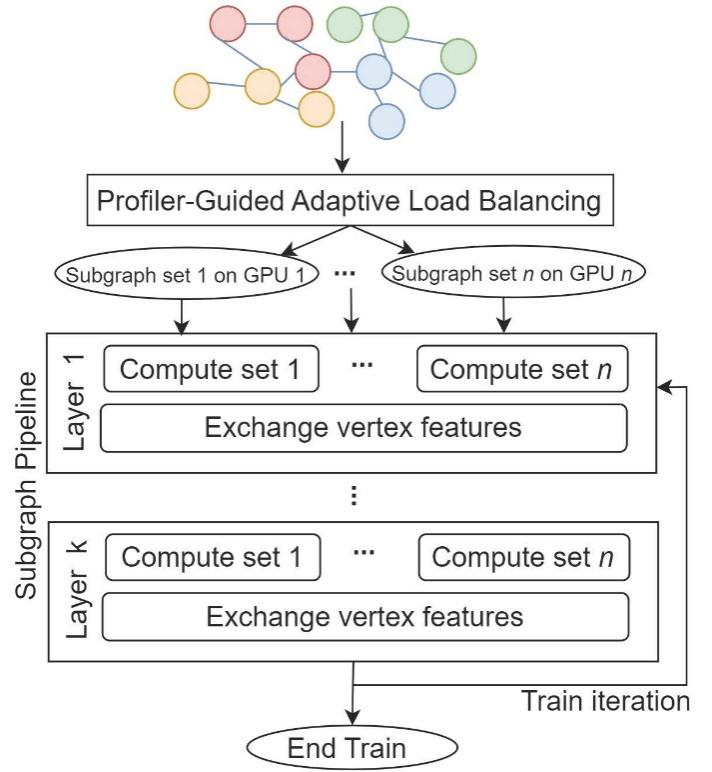
The overview of ParGNN
The first author, Gu Junyu, is a doctoral student at CNIC. The co-first authors include Cao Rongqiang, who is an associate researcher at CNIC, and Li Shunde, also a doctoral student at CNIC. The corresponding author is Wang Jue, a senior engineer at CNIC.
Related work:
Junyu Gu, Shunde Li, Rongqiang Cao, Jue Wang, Zijian Wang, Zhiqiang Liang, Fang Liu, Shigang Li, Chunbao Zhou, Yangang Wang, Xuebin Chi. ParGNN: A Scalable Graph Neural Network Training Framework on multi-GPUs. Proceedings of the 62st ACM/IEEE Design Automation Conference. 2025.