The High-Performance Computing Department Makes Progress in Research on Double Precision Matrix Multiplication Optimization
For the optimization of Double Precision Matrix Multiplication Optimization(DGEMM)on GPU, Li Jialin, a PhD student in High-Performance Department, supported by Prof. ZHANG Jian, proposed a fine-grained prefetching scheme that balances the hardware resources of GPU. This scheme effectively reduces the number of registers used by common blocking methods and improves thread-level parallelism. The research paper was accepted by the International Parallel & Distributed Processing Symposium.
General Matrix Multiplication (GEMM) is one of the fundamental kernels for scientific and high-performance computing. When optimizing the performance of GEMM on GPU, the matrix is usually partitioned into a hierarchy of tiles to fit the thread hierarchy. In practice, the thread-level parallelism is affected not only by the tiling scheme but also by the resources that each tile consumes, such as registers and local data share memory. We present a fine-grained prefetching scheme that improves the thread-level parallelism by balancing the usage of such resources. The gain and loss on instruction and thread level parallelism are analyzed and a mathematical model is developed to estimate the overall performance gain. Moreover, the proposed scheme is integrated into the open-source tool Tensile to automatically generate assembly and tune a collection of kernels to maximize the performance of DGEMM for a family of problem sizes. Experiments show about 1.10X performance speedup on a wide range of matrix sizes for both single and batched matrix-matrix multiplication.
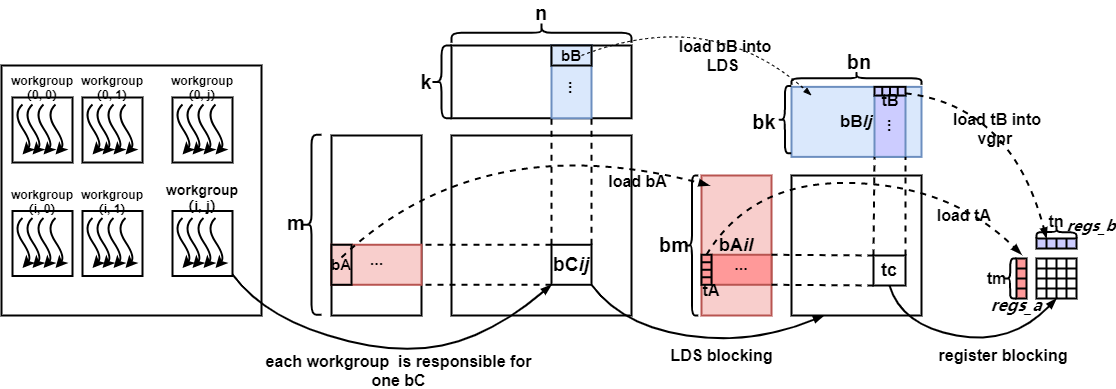
Fig.1. General Two-level Blocking
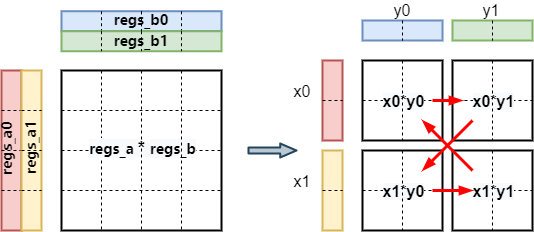
Fig. 2. Fine-Grained Prefetching Scheme for thread tile size 4 ×4
For details, please contact LI Jialin (lijialin@cnic.cn)