Big Data
Date: Jun 09, 2021
To address challenges across the whole research data life circle, the team work on data policies and governance recommendations; develop common technologies to support the management, converged correlation, fast processing and visual analysis of large-scale research data; and constructed tailored user portals to facilitate data-intensive research.
1. Data Policies and Governance
To align policies and governance, a comprehensive data standard system has been established to develop a common language among heterogeneous scientific data resources from various aspects such as data collection, integration, application, service, and effect assessment. More than 40 standards and 5 guidelines have been developed, among which over 10 were polished into national standards.
A series of models have been built to support the governance across the entire data life circle, including the data quality framework, the data quality maturity model, the QFD-based data quality evaluation method, the lightweight data traceability description model, etc.
Several evaluation systems have been designed such as the resource and service evaluation index system, and the expert evaluation system integrating quantitative and qualitative indicators.
2. Distributed Data Integration and Management
A uniformed digital object model was designed to describe heterogeneous scientific data. Based on digital objects, the technical system of data representation, discovery and access has been developed, including tools, software, and data interoperability models and protocols.
With the proposed scalable data management model and scientific database interoperability protocol, the logical and manageable data networks (Web of Data) were built. The VisualDB tools and VDB Cloud (cloud version of VisualDB) have been developed, which provides the functions of RDB and file data management, independent data website publishing, data interface publishing, and all kinds of data services publishing. VisualDB has been applied to 11 national scientific data centers, CAS scientific data center system, etc.
3. Data Convergence Management and Correlation Discovery Technology
Priorities in this direction include multi-source heterogeneous data integration management engine, semantic-based data association network discovery, efficient processing technologies of large-scale scientific data and so on. Relevant results were published by top conferences and journals, and received several software awards in China.
By implementing high-throughput big scientific data pipeline fusion processing engine PiFlow, the processing performance was improved by more than 3 times compared with the mainstream software Apache NiFi.
A symbiotic storage architecture for associating structured and unstructured data and the open source system PandaDB; which supported 100 billion data objects and 10 billion-level correlations and improved the average performance on multi-attribute combination query by more than 1 time compare with the mainstream data management system Neo4j.
The team also developed large-grained data parallel processing technology based on compression perception and two-stage consistency hash data distribution strategy. A test was designed to aggregate 1.114TB 10-dimensional data on a cluster with more than 300 computing cores.
The knowledge mapping system SKS was built and applied by several national agencies.
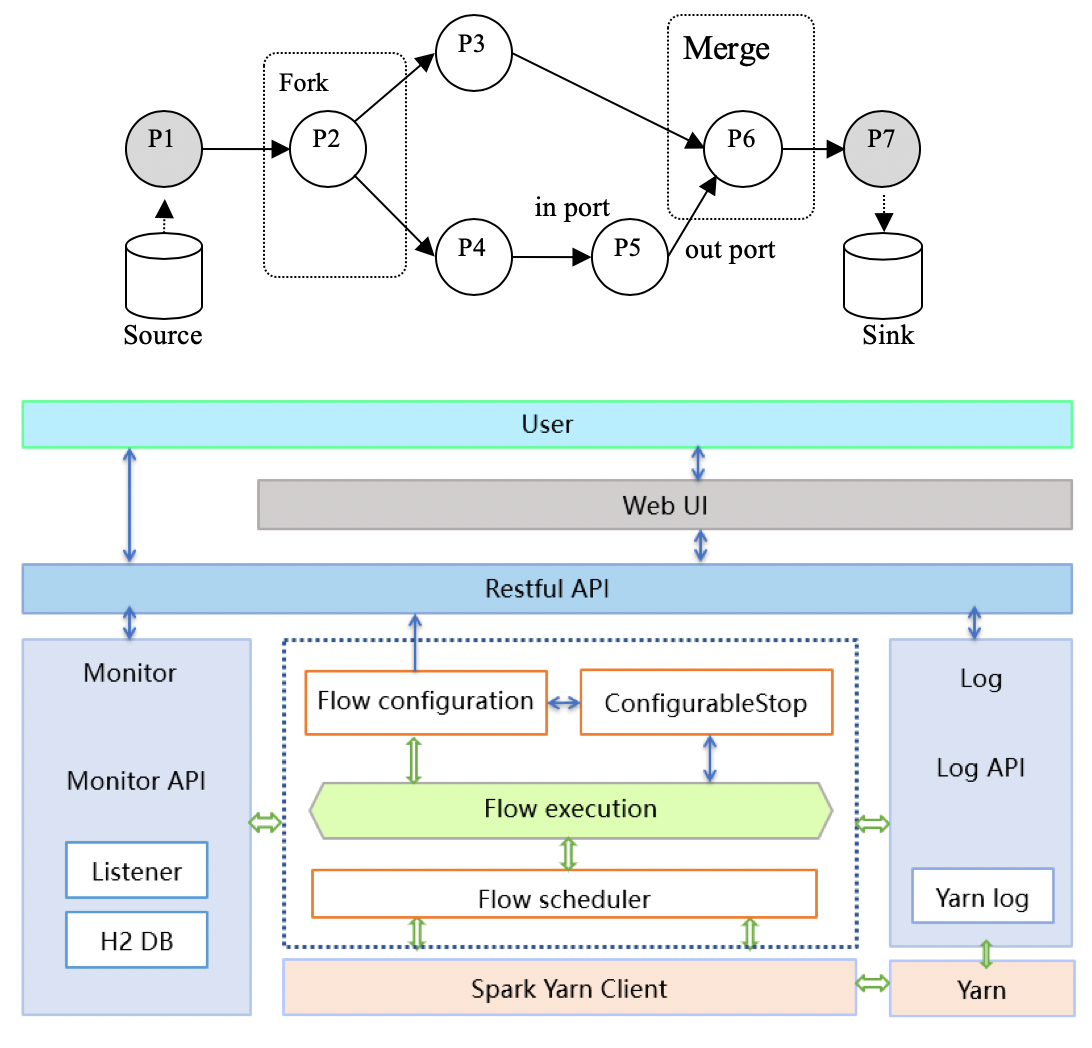
Architecture of PiFlow
4. Data-driven Research Innovation Platform
Data service portals are developed to support scientists in sifting through massive amounts of data and finding novel insights into key research problems.
By working closely with the Big Earth Data Science community, the team developed the large-scale Earth observation data computing engine DataBox (a PB-class grid data engine service technology), and China's first large-scale geospatial data cloud (www.gscloud.cn) with more than 370,000 registered users.
By working closely with biologists, the team developed Darwin Tree, a molecular data analysis and application platform. Botanists are supported in various aspects including to use technical tools to draw a life tree for the research on China's land plant development system framework, to establish and analyze Chinese microtubule plant trees, to reveal the evolutionary history of China's quilt plant system, etc. Research results supported by this service were published in Nature, and selected as one of China’s Top Ten Progress in Life Science in 2018.
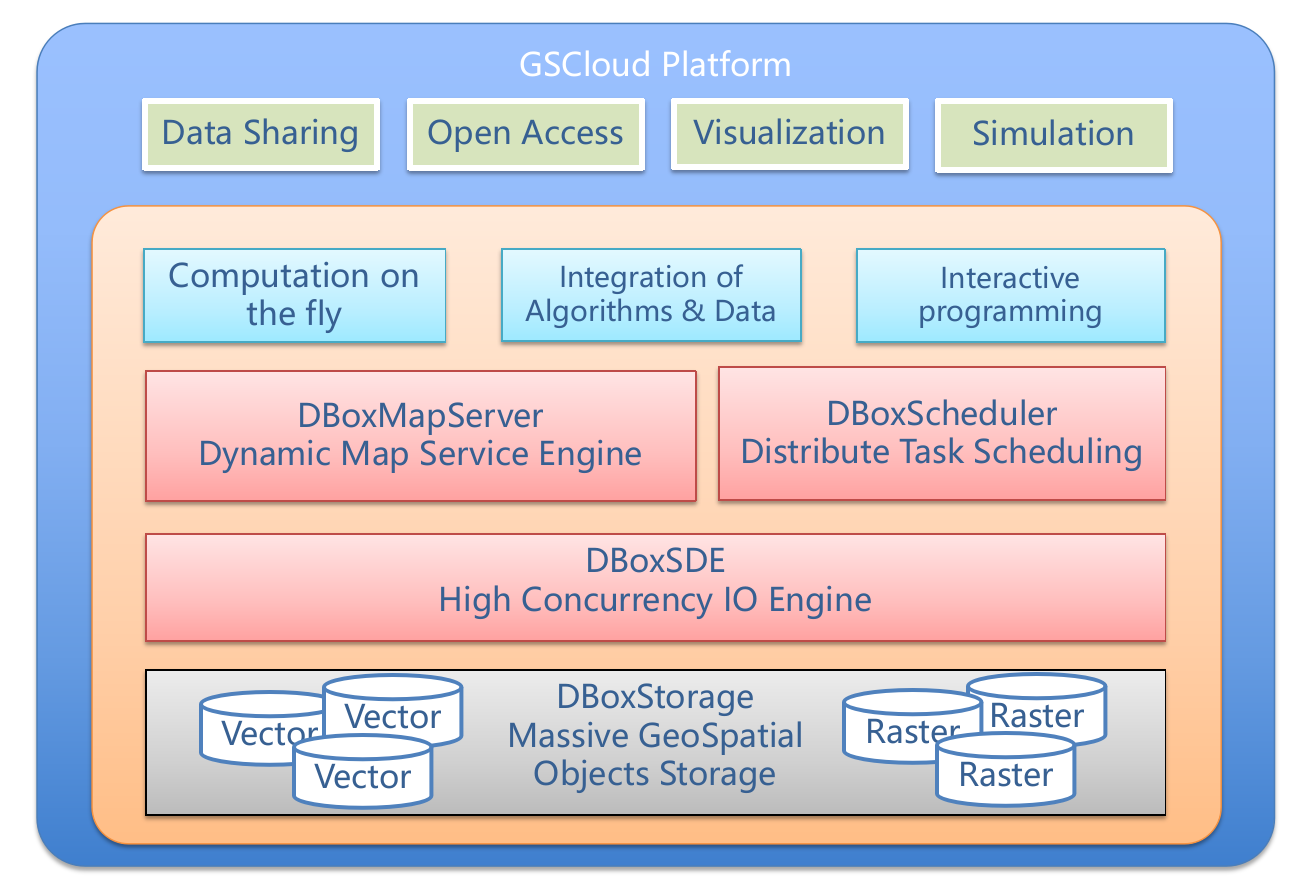
Architecture of GSCloud Platform
5. New Model of Open Data
The team have developed several pilot services to address the challenges of open data for open science. The core elements include two parts, an open data repository to support data stewardship at the bottom, and an open access journal to implement data publication practices.
The data repository Science Data Bank was developed to support the findability, accessibility, interoperability, and reusability of scientific data across various steps such as data submission, storage, integration, management, acquisition and publication.
To understand real-world problems in data publication practices, China Scientific Data was initiated in 2015 as China’s only open access journal for data publication across disciplinary boundaries.
The Blockchain-based Open Data Chain based on distributed ledger construction supports the implementation of distributed institutional nodes by offsite access and facilitates data integrity verification, metadata sharing, version iteration and source traceability. Each piece of data in the federation chain has a permanent identity for supporting data queries and downloads.